안녕하세요! 오늘은 머신러닝의 가장 기본이 되면서도 핵심적인 과정인 데이터 전처리, 회귀/분류 모델링, 그리고 성능 평가까지의 전체 과정을 정리해 보겠습니다.
1. 머신러닝 프로세스 개요 (Machine Learning Pipeline)
| Data Loading | 분석에 필요한 데이터셋을 불러옵니다. (csv, excel, sql 등) · train set (학습용, 레이블 있음) · test set (평가용, 레이블 없음) |
DataSets (All, Train, Test) |
| Data Preprocessing & Feature Engineering | · 결측치 처리, 이상치 처리, 데이터 보정 · Feature Engineering: 기존 데이터를 활용한 신규 데이터 열 생성, 카테고리 데이터 변형(One-Hot Encoding 등) · Feature Selection/Extraction: 중요 데이터 선정 및 상관성이 낮은 불필요한 데이터 삭제 · Data Splitting: 학습용 데이터를 다시 학습(80%)과 학습 평가용(20%)으로 분할 |
데이터 정리본, x_train, y_train, x_valid, y_valid |
| Modeling | 학습할 모델을 생성합니다. · 회귀: 연속형 레이블 (LR, Ridge, Lasso, RF, GB) · 분류: 범주형 레이블 (LR, DT, RF, GB) |
MODEL 인스턴스 |
| Training (fit) | 학습 데이터를 이용해 생성된 모델을 학습시킵니다. · 학습 데이터를 넣어 예측값 출력 $\rightarrow$ pred_train · 학습 평가 데이터를 넣어 예측값 출력 $\rightarrow$ pred_valid |
pred_train, pred_valid |
| Evaluation | 예측값과 실제값을 비교하여 성능을 평가합니다. · 학습 데이터와 학습 평가 데이터의 성능 차이가 너무 크면 과적합 등의 문제가 발생한 것입니다. |
train score, test score |
| Inferencing | 학습된 최종 모델에 실제 예측하고자 하는 데이터(Test Set 또는 미래 데이터)를 넣어 예측합니다. | pred_test |
| Submission | 최종 예측 결과를 양식에 맞춰 제출합니다. | RANK (제출용 파일) |
2. 데이터 전처리 (Data Preprocessing) - 인코딩
머신러닝 모델은 수치형 데이터만 입력받을 수 있기 때문에, 글자로 된 범주형(Categorical) 데이터를 숫자로 변환하는 인코딩 과정이 반드시 필요합니다.
범주형 데이터란?
숫자처럼 연속적인 값이 아니라, 특정한 '범주(Category)' 또는 '이름(Label)'으로 표현되어 의미 있는 그룹으로 구분되는 데이터입니다.
- 성별: 남, 여 (2개 범주)
- 지역: 서울, 부산, 대전 (3개 범주)
- 혈액형: A, B, AB, O (4개 범주)
- 제품등급: 상, 중, 하 (순서가 있는 범주 - Ordinal)
- 불량 여부: 양품, 불량품 (2개 범주)
① 원-핫 인코딩 (One-Hot Encoding)
순서가 없는 범주형 변수를 다룰 때 가장 안전하고 효과적인 방법입니다. 범주의 개수가 너무 많지 않을 때 주로 사용합니다.
- 동작 방식: 각 범주를 새로운 열(Column)로 만들고, 해당하는 데이터에만 1을 부여하고 나머지는 0으로 채웁니다.
- 예: 혈액형(A, B, O) $\rightarrow$ A열(1, 0, 0), B열(0, 1, 0), O열(0, 0, 1)
원-핫 인코딩은 pandas 라이브러리의 get_dummies() 함수를 이용해 아주 쉽게 구현할 수 있습니다.
import pandas as pd
# 1. 샘플 데이터프레임 생성
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'David'],
'blood_type': ['A', 'B', 'O', 'AB']
})
print("원본 데이터:")
print(df)
# 2. One-Hot Encoding 적용
df_encoded = pd.get_dummies(df, columns=['blood_type'])
print("\nOne-Hot Encoding 결과:")
print(df_encoded)
레이블 인코딩 (Label Encoding)
문자형 데이터를 단순 정수형 숫자로 일대일 매핑하여 변환하는 간단한 방법입니다.
- 언제 사용하나요?
- 상 < 중 < 하, 초급 < 중급 < 고급과 같이 순서(우선순위)가 있는 범주형 변수를 처리할 때 유용합니다.
- 혹은 범주의 종류가 너무 많아 원-핫 인코딩을 적용하면 열이 너무 늘어날 때 대안으로 사용합니다.
- 트리 기반 모델(Random Forest, XGBoost 등)은 데이터에 순서가 없어도 숫자의 크기에 왜곡되지 않고 처리를 잘해줍니다.
- 동작 방식: 중복을 제거한 고유값들을 글자 순서(사전순)대로 정렬한 뒤, 0부터 순서대로 숫자를 부여합니다.
- 예: 만족도(만족, 보통, 불만) $\rightarrow$ 글자 정렬 시 '만족', '보통', '불만' 순서에 따라 정수 할당
레이블 인코딩은 scikit-learn 라이브러리의 LabelEncoder 클래스를 사용합니다.
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 예시 데이터 생성
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie', 'David'],
'satisfaction': ['만족', '보통', '보통', '불만']
})
print("원본 데이터:")
print(df)
# LabelEncoder 객체 생성 및 학습/변환
le = LabelEncoder()
# 데이터를 학습(fit)하여 규칙을 정의합니다.
le.fit(df['satisfaction'])
print("\n# le.classes_ 확인 (인코딩된 범주 목록):")
print(le.classes_)
# 실제 데이터 변환(transform) 수행
df['satisfaction_encoded'] = le.transform(df['satisfaction'])
# 만약 한 번에 하려면 아래 한 줄로도 가능합니다.
# df['satisfaction_encoded'] = le.fit_transform(df['satisfaction'])
print("\nLabel Encoding 결과:")
print(df)

3. 데이터 단위 맞추기: 스케일링 (Scaling)
피처들의 단위와 스케일(값의 범위)이 서로 다르면 모델 학습 과정에서 편향이 발생할 수 있습니다.
- 예시 상황:
- 키(cm): $160 \sim 190$ (최대-최소 차이: 30)
- 연봉(만원): $1,000 \sim 10,000$ (최대-최소 차이: 9,000)
- 이 경우, 연봉의 스케일이 압도적으로 크기 때문에 모델은 '키' 변수를 무시하고 '연봉' 변수만을 바탕으로 편향되게 학습을 진행할 위험이 있습니다.
① StandardScaler (표준화)
각 변수의 값을 평균이 0, 표준편차가 1인 표준정규분포를 따르도록 변환하는 방법입니다.
- 수식:


- 특징: 데이터의 전체적인 분포 모양(곡선 형태)은 유지하면서 중심축을 0으로 이동시키고 양옆으로 크기만 조절합니다. 데이터가 정규분포에 가깝거나 대칭적일 때 유용합니다.
- 주의: 이상치(Outlier)가 있을 경우 평균과 표준편차 계산이 크게 왜곡될 수 있습니다.
실습 코드
from sklearn.preprocessing import StandardScaler
# 예시 데이터 (5개의 샘플, 2개의 특성)
X_train = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
# StandardScaler 초기화 및 변환
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
print("StandardScaler 적용 결과:")
print(X_train_scaled)
② MinMaxScaler (정규화)
모든 데이터 값을 최소값 0, 최대값 1 사이의 범위로 압축하여 변환하는 기법입니다.
- 수식:

- 특징: 데이터의 범위를 일정한 구간으로 명확히 제한하고 싶을 때 사용하며, 데이터 분포가 특정 방향으로 치우쳐 있는 비정규분포 형태일 때 유용합니다.
- 주의: 이상치(Outlier)가 단 하나라도 존재하면 전체 데이터 범위가 극단적으로 좁게 압축되어 다른 데이터 간의 미세한 차이를 분별하기 어려워질 수 있습니다.
실습 코드
from sklearn.preprocessing import MinMaxScaler
# 예시 데이터 (5개의 샘플, 2개의 특성)
X_train = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
# MinMaxScaler 초기화 및 변환
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
print("MinMaxScaler 적용 결과:")
print(X_train_scaled)
스케일러가 강력한 성능을 발휘할 때: SVM (Support Vector Machine)
SVM 모델처럼 피처의 스케일에 매우 민감한 모델은 스케일 조정을 통해 데이터 간 거리 계산이 공정해지면서 훨씬 안정적이고 정밀한 결정 경계(Decision Boundary)를 형성하게 됩니다.

4. 머신러닝의 난제: 과적합과 다중공선성
① 과적합 (Overfitting) 이란?
머신러닝 모델이 훈련용 데이터(Train Data)에 너무 과하게 최적화되어, 새로운 데이터(Test Data)를 예측할 때 성능이 뚝 떨어지는 현상을 말합니다.
- 상황 예시: Train Data에서는 100점 만점을 받지만, 정작 실전인 Test Data를 넣으면 20점밖에 받지 못하는 현상입니다.
- 발생 원인:
- 모델이 너무 복잡할 때 (너무 많은 파라미터나 과도하게 깊은 트리 기법 사용)
- 학습을 위한 데이터의 전체 양이 절대적으로 부족할 때
- 데이터 자체에 노이즈(잡음)나 극단적인 이상치가 너무 많아 모델이 쓸데없는 오차 정보까지 전부 학습해버릴 때
- 해결 방법:
- 모델 복잡도 줄이기: 단순하고 간결한 모델 구조를 채택합니다.
- 데이터 추가 확보: 데이터 수집을 통해 더 넓은 범위의 일반적인 경향을 모델에 학습시킵니다.
- 규제(Regularization): L1(Lasso), L2(Ridge) 등의 규제 기법으로 불필요하게 가중치가 비대해지는 것을 방지합니다.
- 교차 검증(Cross Validation): 데이터를 여러 번 쪼개서 학습과 테스트를 반복 평가해 과적합 징후를 조기에 포착합니다.

② 다중공선성 (Multicollinearity) 이란?
머신러닝 학습 모델에 들어가는 독립 변수(Feature)들끼리 너무 강력하게 상관되어 있어 발생하는 현상입니다.
- 영향: 독립 변수 간의 중복된 정보가 너무 많아지면 선형 회귀 분석 모델에서는 가중치 추정이 불안정해져 해석 능력이 훼손되고 정확도가 하락할 수 있습니다.
- 비선형 모델(Random Forest, XGBoost 등)과 다중공선성:
- 트리 기반의 비선형 모델은 변수 간의 독립성을 전제하지 않기 때문에 다중공선성의 영향을 크게 받지 않으며, 예측 결과 자체도 잘 유지되는 편입니다.
- 하지만 비선형 모델이라 할지라도 중복 정보가 지나치게 많아지면 모델의 복잡도가 불필요하게 증가(과적합 위험)하고, 중요 변수를 파악하는 특성 중요도(Feature Importance) 해석이 크게 왜곡될 수 있습니다.
다중공선성 해결 기법 3가지
- VIF(Variance Inflation Factor) 기반 변수 제거:
- 각 변수마다 VIF 지수를 측정하여, VIF가 10 이상인 경우 다른 변수로 충분히 설명할 수 있는 중복 신호로 취급하고 변수를 하나씩 차례로 소거합니다. (제거 후 남은 변수로 다시 VIF를 구하는 과정을 반복)
- 높은 상관관계를 가진 변수 직접 제거:
- 피어슨 상관행렬(Pearson Correlation)을 구한 뒤 두 변수 간의 상관계수가 0.9를 초과하는 쌍을 찾고, 도메인 지식을 고려하여 불필요한 하나를 골라 제거합니다.
- PCA(Principal Component Analysis, 주성분 분석):
- 중복되는 여러 독립 변수들을 완전히 지우는 대신, 정보를 최대한 보존하면서 서로 수직인 가상의 새로운 축(주성분)들로 차원을 결합하여 축소하는 방식입니다. 다만, 분석 이후 피처의 해석력이 떨어진다는 단점이 있습니다.
다중공선성은 언제나 무조건 처리해야 할까요?
- 모델링의 목적이 '해석(Interpretation)'인 경우: 독립 변수들이 각 결과에 미치는 정밀한 영향도를 알아야 하므로 VIF와 도메인 지식을 동원해 무조건 처리해야 합니다.
- 모델링의 목적이 순수 '예측(Prediction)'인 경우: 정확히 결과 수치만 도출하는 것이 목적이라면 굳이 복잡하게 변수를 지우고 축소할 필요 없이 머신러닝 학습 모델의 예측 파워를 유지하기 위해 다중공선성을 방치해도 괜찮습니다.

5. 데이터 분할 (Data Splittin
g)
훈련용 데이터(Train)와 검증/평가용 데이터(Test)를 정밀하게 분배하는 단계입니다. 학습용 모의고사 데이터셋을 쪼개어 일부는 평가용 모의고사(validation)로 남겨두는 작업입니다.
실습 코드
scikit-learn에서 제공하는 train_test_split 모듈을 사용합니다. stratify 옵션을 쓰면 정답 레이블의 불균형 비율을 훈련셋과 테스트셋에 똑같이 복사하여 깔끔하게 분할할 수 있습니다.
import pandas as pd
from sklearn.model_selection import train_test_split
# 예시 불균형 데이터 생성
data = {
'feature1': range(100),
'feature2': range(100, 200),
'label': [0]*80 + [1]*20 # 80:20의 불균형 데이터
}
df = pd.DataFrame(data)
# X(입력) 변수와 y(정답 레이블) 분리
X = df[['feature1', 'feature2']]
y = df['label']
# 데이터 분할 (30%를 테스트 데이터로 설정, stratify를 지정해 정답 비율을 유지합니다.)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 최종 결과 확인
print("훈련 데이터 크기:", X_train.shape)
print("테스트 데이터 크기:", X_test.shape)
6. 회귀 분석 및 평가 (Regression & Evaluation)
① 회귀 분석 개요
연속적인 실수 값을 예측하기 위한 지도학습 모델입니다.
- 선형회귀 (Simple Linear Regression):


회귀 모델 실습 1 (단순 선형회귀)
scikit-learn에서 머신러닝 학습 모델을 생성하는 공통 패러다임은 언제나 동일합니다.
- clf = 모델명() (인스턴스 생성)
- clf.fit(X_train, y_train) (모델 학습)
- y_pred = clf.predict(X_test) (결과 예측)
- 평가지표(y_test, y_pred) (예측 성능 확인)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 데이터 준비
X = [[1], [2], [3], [4], [5]]
y = [2, 4, 6, 8, 10]
# 학습 및 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 인스턴스 선언 및 지도학습 진행
model = LinearRegression()
model.fit(X_train, y_train)
③ 회귀 모델 성능 평가 지표
회귀 평가 지표들은 모델의 예측값과 실제값 사이의 잔차(Residual, 오차)를 다양한 방법으로 계산해 냅니다.
1. 절대 오차 (MAE, Mean Absolute Error)
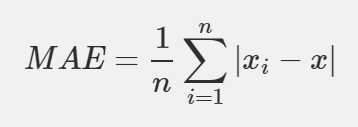
실제값과 예측값 차이의 절대값을 전부 더해 평균을 낸 것입니다. 오차의 절대적인 스케일을 왜곡 없이 직관적으로 나타내 줍니다.
2. 평균 제곱 오차 (MSE, Mean Squared Error)

오차를 제곱해서 평균을 계산합니다. 제곱 연산의 특성상 실제값과 멀어진 큰 오차에 압도적인 가중 처벌(페널티)을 부여합니다. 다만 단위가 본래 가격의 '원' 단위에서 '원²' 단위로 변형되므로 직관적 분석이 다소 난해합니다.
from sklearn.metrics import mean_squared_error
# 예시 데이터 (실제 값과 예측 값)
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
# MSE 계산
mse = mean_squared_error(y_true, y_pred)
print("MSE:", mse)
3. 평균 제곱근 오차 (RMSE, Root Mean Squared Error)
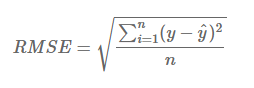
MSE에 루트를 씌워 본래 타겟 데이터의 실제 스케일 단위로 오차 수준을 복구시킨 지표입니다. 오차 평균의 직관성을 보장합니다.
from sklearn.metrics import mean_squared_error
import numpy as np
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mse = mean_squared_error(y_true, y_pred)
# 제곱근 변환
rmse = np.sqrt(mse)
print("RMSE:", rmse)
4. 결정 계수 ($R^2$, R-squared)

모델이 실제 타겟의 전체 변동성 중 얼마나 많은 비율을 부드럽게 설명해내고 있는지를 뜻하는 수치입니다. 1에 수렴할수록 완벽히 작동하는 훌륭한 모델입니다.
- 빨간 선: 모델의 예측값 / SSE: 오차.
- 결정계수 = 1-(모형에 의해 설명이 되지 않는 변동/Y의 전체 변동)

from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
r2 = r2_score(y_true, y_pred)
print("R² 스코어:", r2)
④ 다중 선형회귀 (Multiple Linear Regression)
두 개 이상의 풍부한 여러 독립 변수(Feature)들을 함께 고려하여 복합적으로 정답을 수치 예측하는 알고리즘입니다.
- 수식:

실습 코드
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 독립 변수 (x1, x2) 다차원 행렬 준비
X = np.array([[1, 2], [2, 3], [3, 5], [4, 6], [5, 8]])
# 종속 변수 y 준비
y = np.array([3, 5, 7, 9, 11])
# 학습 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 다중 회귀 모델 생성 및 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 파라미터 값 추출 및 결과 출력
print("회귀 계수 (W):", model.coef_) # 각 가중치 배열
print("절편 (b):", model.intercept_) # 절편
print("X_test 입력값:\n", X_test)
y_pred = model.predict(X_test)
print("최종 모델의 예측값:", y_pred)
7. 분류 모델 및 평가 (Classification & Evaluation)
① 분류 분석 개요
미리 정의해 둔 불연속 범주 그룹에 맞추어 대상을 정밀하게 분류하는 지도학습 모델입니다. (정답 레이블이 없는 군집 분석과 명확히 구별됩니다.)
- 종류: 이진 분류 (0이냐 1이냐), 다중 분류 (여러 클래스 분류)
② 로지스틱 회귀 분석 (Logistic Regression)
종속 변수가 범주형 데이터일 때 사용하며, 겉으로는 회귀 식을 쓰지만 실제로는 강력한 분류 알고리즘으로 사용됩니다.
- 선형 회귀의 확률 예측 실패:
- 만약 분류 과제를 일반 선형 회귀 모델로 계산한다면 예측 결과가 음수가 되거나 1을 초과하게 될 위험이 있습니다.
- 로지스틱의 해법:
- 선형 예측 결과를 S자 곡선인 시그모이드 함수(Sigmoid Function)에 넣어 출력값을 항상 0~1 사이의 안전한 확률 값으로 강제 정제합니다.
③ 분류 모델의 상세 성능 평가 지표
1. 혼동 행렬 (Confusion Matrix)
예측 범주와 실제 범주의 일치 여부를 아래 표 형식으로 나타낸 오차 행렬입니다. scikit-learn에서는 정답 클래스가 0, 1 순서에 따라 아래 배치 규칙을 가집니다.
실제값 (Actual) \ 예측값 (Predicted)Negative (0)Positive (1)
| Negative (0) | TN (True Negative) | FP (False Positive) |
| Positive (1) | FN (False Negative) | TP (True Positive) |
- True Positive (TP): Positive(1)로 예측했고 실제로 맞춤
- False Negative (FN): Negative(0)로 예측했으나 실제로는 Positive(1)임 (틀림)
- False Positive (FP): Positive(1)로 예측했으나 실제로는 Negative(0)임 (틀림)
- True Negative (TN): Negative(0)로 예측했고 실제로 맞춤
2. 정확도, 정밀도, 재현율, F1-Score 수식
- 정확도 (Accuracy): (TP+TN)/(TP+FN+FP+TN)
- 전체 예측 데이터 중 정답을 맞춘 종합적 성공 비율입니다. 데이터 분포 불균형 시 정확도가 높은 착시가 생길 수 있습니다.
- 정밀도 (Precision):$$\text{Precision} = TP/(TP+FP)
- 모델이 Positive(1)라고 강력히 우긴 데이터 중 진짜 정답이었던 비율입니다.
- 정밀도는 의사가 아주 확실하다고 확신할 때만 소극적으로 판정을 내리면 올리기 편합니다.
- 재현율 (Recall, 민감도):$$\text{Recall} = TP/(TP+FN)
- 실제 존재하던 전체 Positive(1) 데이터들 중 빠트리지 않고 모델이 몇 %나 잡아냈는지 비율입니다.
- 암 환자 검출, 기계 불량 분석처럼 실제 대상을 절대로 놓치면 안 될 때 매우 중요하게 취급하는 지표입니다. (모든 사람에게 무조건 암이라고 양성 판정을 남발하면 재현율은 쉽게 100%에 도달합니다.)
- F1-Score: 2TP/(2TP+FP+FN)
- 정밀도와 재현율이 한쪽으로 극단적으로 치우치지 않게 조화평균(Harmonic Mean)을 내어 모델 성능을 객관적으로 가늠하는 최고의 범용 지표입니다.
④ ROC 커브와 AUC (임계값 무관성 평가)
분류 예측에 쓰이는 임계값(Threshold, 예: 0.5 확률 기준을 0.3이나 0.7로 바꿈)을 연속적으로 이동시킴에 따른 TPR(참양성률, 재현율)과 FPR(거짓양성률, 오탐지율)의 궤적 좌표를 연결한 곡선입니다.
- FPR (False Positive Rate): 실제 음성인데 모델이 양성이라고 삽질 예측한 비율 ($FP / (FP + TN)$)
- TPR (True Positive Rate): 실제 양성인데 양성으로 정확히 구조해 낸 비율 (Recall)
- 평가: ROC 커브가 왼쪽 위 모서리에 바짝 붙어 사각형에 채워질수록, 또 대각선(랜덤 무작위 찍기 선, AUC=0.5)에서 멀어져 위로 아치형을 그릴수록 완벽한 모델입니다. 이때 곡선 아래 면적의 크기를 수치화한 것이 AUC(Area Under Curve) 지표이며, 이상적 성능의 완벽한 모델은 AUC = 1.0을 기록합니다.
⑤ 불균형 분포 클래스 평균 계산법: Macro vs Weighted
전체 제품 수 100개 중 정상 제품(90개), 불량 제품(10개)인 극단적인 제조 라인 불량 분류 데이터를 가정해 보겠습니다.
- 클래스 A (정상): 데이터 90개, 성능 스코어: 0.90 (우수)
- 클래스 B (불량): 데이터 10개, 성능 스코어: 0.10 (불량)
이 경우 두 클래스의 평균 성적을 매기는 방법에는 큰 차이가 생깁니다.
1. Macro Average (매크로 평균)
데이터 규모 편차에 전혀 현혹되지 않고, 개별 클래스들의 성능 자체만을 동급 일대일 기준선에 올려 평균을 냅니다.

- 해석: 최종 성적표가 0.50으로 급격히 폭락하게 됩니다. 이는 소수 클래스인 불량품 탐지에서 끔찍한 실적을 거두었다는 모델의 실제 민낯을 여과 없이 처벌하여 투명하게 드러내 줍니다.
2. Weighted Average (가중 평균)
각 클래스가 소유한 원본 데이터 크기 비율을 가중치로 보정 연산하여 합산 평균을 냅니다.

- 해석: 최종 평가 지표가 0.82라는 준수한 수치로 높게 포장됩니다. 하지만 이는 90% 비중의 다수 정상 데이터가 거둔 우수한 점수 뒤로 소수 클래스의 저조한 예측 실적이 가려지는 치명적인 '착시 현상'입니다.
구분연산 의미권장 활용 가이드잠재 리스크
| Macro Avg | 클래스간 철저한 평등 분배 | 소수 클래스를 타겟팅하는 암 예방 진단, 사기 감지, 극소수 불량 탐지 분야 | 소수 점수에 깎여 모델의 주류 분류 성적이 과소평가될 소지가 있습니다. |
| Weighted Avg | 다수결 비중 가중 원칙 | 전체 데이터 분류 처리량(볼륨) 관점에서의 종합 성능 평가가 필요할 때 | 불량품을 한 개도 거르지 못해도 점수가 높게 나와 오판할 수 있습니다. |